Expressions
Overview
You can use expressions in multiple places in OpenRefine to extend data cleanup and transformation. Expressions are available with the following functions:
- :
- (click “change” after they have been created to bring up an expressions window)
- :
- :
- .
In the expressions editor window you have the opportunity to select a supported language. The default is GREL (General Refine Expression Language); OpenRefine also comes with support for Clojure and Jython. Extensions may offer support for more expressions languages.
These languages have some syntax differences but support many of the same variables. For example, the GREL expression value.split(" ")[1] would be written in Jython as return value.split(" ")[1].
This page is a general reference for available functions, variables, and syntax. For examples that use these expressions for common data tasks, look at the Recipes section on the wiki.
Expressions
There are significant differences between OpenRefine's expressions and the spreadsheet formulas you may be used to using for data manipulation. OpenRefine does not store formulas in cells and display output dynamically: OpenRefine’s transformations are one-time operations that can change column contents or generate new columns. These are applied using variables such as value or cell to perform the same modification to each cell in a column.
Take the following example:
| ID | Friend | Age |
|---|---|---|
| 1. | John Smith | 28 |
| 2. | Jane Doe | 33 |
Were you to apply a transformation to the “friend” column with the expression
value.split(" ")[1]
OpenRefine would work through each row, splitting the “friend” values based on a space character. The value for row 1 is “John Smith” so the output would be “Smith” (as "[1]" selects the second part of the created output); the value for row 2 is “Jane Doe” so the output would be “Doe”. Using variables, a single expression yields different results for different rows. The old information would be discarded; you couldn't get "John" and "Jane" back unless you undid the operation in the History tab.
For another example, if you were to create a new column based on your data using the expression row.starred, it would generate a column of true and false values based on whether your rows were starred at that moment. If you were to then star more rows and unstar some rows, that data would not dynamically update - you would need to run the operation again to have current true/false values.
Note that an expression is typically based on one particular column in the data - the column whose drop-down menu is first selected. Many variables are created to stand for things about the cell in that “base column” of the current row on which the expression is evaluated. There are also variables about rows, which you can use to access cells in other columns.
The expressions editor
When you select a function that accepts expressions, you will see a window overlay the screen with what we call the expressions editor.
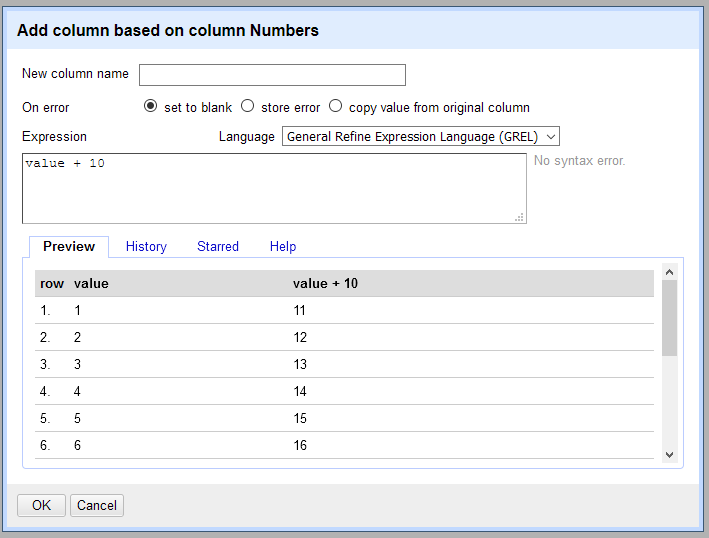
The expressions editor offers you a field for entering your formula and shows you a preview of its transformation on your first few rows of cells.
There is a dropdown menu from which you can choose an expression language. The default at first is GREL; if you begin working with another language, that selection will persist across OpenRefine. Jython and Clojure are also offered with the installation package, and you may be able to add more language support with third-party extensions and customizations.
There are also tabs for:
- History, which shows you formulas you’ve recently used from across all your projects
- Starred, which shows you formulas from your History that you’ve starred for reuse
- Help, a quick reference to GREL functions.
Starring formulas you’ve used in the past can be helpful for repetitive tasks you’re performing in batches.
You can also choose how formula errors are handled: replicate the original cell value, output an error message into the cell, or ouput a blank cell.
Regular expressions
OpenRefine offers several fields that support the use of regular expressions (regex), such as in a or a operation. GREL and other expressions can also use regular expression markup to extend their functionality.
If this is your first time working with regex, you may wish to read this tutorial specific to the Java syntax that OpenRefine supports. We also recommend this testing and learning tool.
GREL-supported regex
To write a regular expression inside a GREL expression, wrap it between a pair of forward slashes (/) much like the way you would in Javascript. For example, in
value.replace(/\s+/, " ")
the regular expression is \s+, and the syntax used in the expression wraps it with forward slashes (/\s+/). Though the regular expression syntax in OpenRefine follows that of Java (normally in Java, you would write regex as a string and escape it like "\s+"), a regular expression within a GREL expression is similar to Javascript.
Do not use slashes to wrap regular expressions outside of a GREL expression.
On the GREL functions page, functions that support regex will indicate that with a “p” for “pattern.” The GREL functions that support regex are:
Jython-supported regex
You can also use regex with Jython expressions, instead of GREL, for example with a :
python import re g = re.search(ur"\u2014 (.*),\s*BWV", value) return g.group(1)
Clojure-supported regex
Clojure uses the same regex engine as Java, and can be invoked with re-find, re-matches, etc. You can use the #"pattern" reader macro as described in the Clojure documentation. For example, to get the nth element of a returned sequence, you can use the nth function:
clojure (nth (re-find #"\u2014 (.*),\s*BWV" value) 1)
Variables
Most OpenRefine variables have attributes: aspects of the variables that can be called separately. We call these attributes “member fields” because they belong to certain variables. For example, you can query a record to find out how many rows it contains with row.record.rowCount: rowCount is a member field specific to the record variable, which is a member field of row. Member fields can be called using a dot separator, or with square brackets (row["record"]). The square bracket syntax is also used for variables that can call columns by name, for example, cells["Postal Code"].
| Variable | Meaning |
|---|---|
value | The value of the cell in the current column of the current row (can be null) |
row | The current row |
row.record | One or more rows grouped together to form a record |
cells | The cells of the current row, with fields that correspond to the column names (or row.cells) |
cell | The cell in the current column of the current row, containing value and other attributes |
cell.recon | The cell's reconciliation information returned from a reconciliation service or provider |
rowIndex | The index value of the current row (the first row is 0) |
columnName | The name of the current cell's column, as a string |
Row
The row variable itself is best used to access its member fields, which you can do using either a dot operator or square brackets: row.index or row["index"].
| Field | Meaning |
|---|---|
row.index | The index value of the current row (the first row is 0) |
row.cells | The cells of the row, returned as an array |
row.columnNames | An array of the column names of the project. This will report all columns, even those with null cell values in that particular row. Call a column by number with row.columnNames[3] |
row.starred | A boolean indicating if the row is starred |
row.flagged | A boolean indicating if the row is flagged |
row.record | The record object containing the current row |
For array objects such as row.columnNames you can preview the array using the expressions window, and output it as a string using toString(row.columnNames) or with something like:
forEach(row.columnNames,v,v).join("; ")
Cells
The cells object is used to call information from the columns in your project. For example, cells.Foo returns a cell object representing the cell in the column named “Foo” of the current row. If the column name has spaces, use square brackets, e.g., cells["Postal Code"]. To get the corresponding column's value inside the cells variable, use .value at the end, for example, cells["Postal Code"].value. There is no cells.value - it can only be used with member fields.
Cell
A cell object contains all the data of a cell and is stored as a single object.
You can use cell on its own in the expressions editor to copy all the contents of a column to another column, including reconciliation information. Although the preview in the expressions editor will only show a small representation (“[object Cell]”), it will actually copy all the cell's data. Try this with → .
| Field | Meaning | Member fields |
|---|---|---|
cell | An object containing the entire contents of the cell | .value, .recon, .errorMessage |
cell.value | The value in the cell, which can be a string, a number, a boolean, null, or an error | |
cell.recon | An object encapsulating reconciliation results for that cell | See the reconciliation section |
cell.errorMessage | Returns the message of an EvalError instead of the error object itself (use value to return the error object) | .value |
Reconciliation
Several of the fields here provide the data used in reconciliation facets. You must type cell.recon; recon on its own will not work.
| Field | Meaning | Member fields |
|---|---|---|
cell.recon.judgment | A string: either “matched”, "new”, "none” | |
cell.recon.judgmentAction | A string: either "single” or “similar” (or “unknown”) | |
cell.recon.judgmentHistory | A number, the epoch timestamp (in milliseconds) of your judgment | |
cell.recon.matched | A boolean, true if judgment is “matched” | |
cell.recon.match | The recon candidate that has been matched against this cell (or null) | .id, .name, .type |
cell.recon.best | The highest scoring recon candidate from the reconciliation service (or null) | .id, .name, .type, .score |
cell.recon.features | An array of reconciliation features to help you assess the accuracy of your matches | .typeMatch, .nameMatch, .nameLevenshtein, .nameWordDistance |
cell.recon.features.typeMatch | A boolean, true if your chosen type is “matched” and false if not (or “(no type)” if unreconciled) | |
cell.recon.features.nameMatch | A boolean, true if the cell and candidate strings are identical and false if not (or “(unreconciled)”) | |
cell.recon.features.nameLevenshtein | A number representing the Levenshtein distance: larger if the difference is greater between value and candidate | |
cell.recon.features.nameWordDistance | A number based on the word similarity | |
cell.recon.candidates | An array of the top 3 candidates (default) | .id, .name, .type, .score |
The cell.recon.candidates and cell.recon.best objects have a few deeper fields: id, name, type, and score. type is an array of type identifiers for a list of candidates, or a single string for the best candidate.
Arrays such as cell.recon.candidates and cell.recon.candidates.type can be joined into lists and stored as strings with something like:
forEach(cell.recon.candidates,v,v.name).join("; ")
Record
A row.record object encapsulates one or more rows that are grouped together, when your project is in records mode. You must call it as row.record; record will not return values.
| Field | Meaning |
|---|---|
row.record.index | The index of the current record (starting at 0) |
row.record.cells | An array of the cells in the given column of the record |
row.record.fromRowIndex | The row index of the first row in the record |
row.record.toRowIndex | The row index of the last row in the record + 1 (i.e. the next record) |
row.record.rowCount | A count of the number of rows in the record |
For example, you can facet by number of rows in each record by creating a (or a ) and entering row.record.rowCount.